
Introduction
TensorFlow is an open-source, high performance library for numerical computation that uses directed acyclic graphs (DAGs). DAGs are simply graphs that flows in one direction, and can be used to represent various computations, such as addition, subtraction etc. A tensor is an N-dimensional array of data. It’s currently the most popular ML library on Github due to the community around it. TensorFlow is normally used to design and build Neural Networks (NNs).
Google TensorFlow is an ML toolkit/library suitable for ML applications requiring significant processing and compute power, especially when training on larger datasets, such as organisational data, customer data or image banks from cameras mounted on vehicles. The outcome here could be customer insights, segmentation, gaming applications, and so on. It is typically used for training and inference of Deep Neural Networks (DNNs), i.e. Neural Networks with multiple layers, that may require more intensive computation.
TensorFlow is designed to achieve faster computation by distributing the work across a multitude of GPUs. This works great for training and deploying DNNs. Therefore, it’s considered a good idea to deploy it on cloud hosted servers, to be able to leverage many powerful GPUs at once. However, it may not be as good of an idea if you have a small dataset and network required for training. In this case, it may be sufficient to rely on libraries such as scikit-learn for development.
TensorFlow Abstraction Layers
| Layer | Description |
| tf.estimator, tf.keras, tf.data | High-Level API for distributed training |
| tf.losses, tf.metrics, tf.optimizers, etc | Components useful when building custom NN models |
| Core TensorFlow (Python) | Python API Gives you full control |
| Core TensorFlow (C++) | Low Level C++ API |
| GPU, CPU, TPU, Android | Hardware |
Following this, Google promotes Vertex AI as an orthogonal service to these layers, meaning that you can run all layers on the Cloud, without having to install any software or manage any servers. For the ML engineer certificate, you will need to focus on understanding the top three layers in the table.
Tensor Structure
All tensors are immutable like python numbers and strings: you can never update the contents of a tensor, only create a new one. Note that, as mentioned before, a Tensor is an array of N-dimensional data.
See below table for the structure of tensors.
| Assigned Name | Rank (Dimension) | Example | Shape Example | Shape Explanation |
| Scalar | 0 | x = tf.constant(3) | () | 0 rows, 0 columns (i.e. constant) |
| Vector | 1 | x = tf.constant([3, 5, 7]) | (3,) | 3 rows, 0 columns (i.e. list/array) |
| Matrix | 2 | x = tf.constant([[3, 5, 7], [4, 6 , 8]]) | (2, 3) | 2 rows, 3 columns (i.e. matrix) |
| 3D Tensor | 3 | tf.constant([[[3, 5, 7], [4, 6, 8]]], [[1, 2, 3], [4, 5, 6])]) | (2, 2, 3) | 3D Matrix (x, y, z shape) |
| nD Tensor | n | x1 = tf.constant([2, 3, 4])x2 = tf.stack([x1, x1])x3 = tf.stack([x2, x2, x2, x2])x4 = tf.stack([x3, x3])... | (3,)(2, 3)(4, 2, 3)(2, 4, 2, 3) | 4D + (n-4) |

Scalar
[]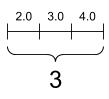
Vector
[3]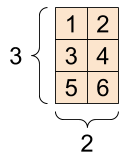
[3,2]A 3-axis tensor, shape [3, 2, 5]
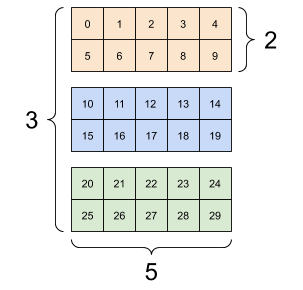
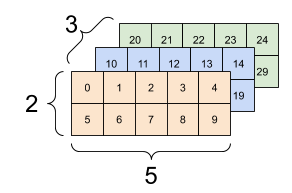
3D Front View
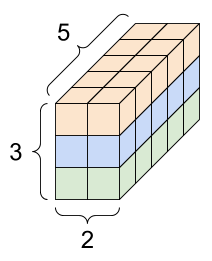
3D Block

[3, 2, 4, 5]Tensors behave similar to n-dimensional numpy arrays, except that
tf.constantproduces constant tensorstf.Variableproduces tensors that can be modified
tf.shape is a way to check the dimensions of the tensors.
To change the value of a tensorflow variable, x, you can use
- x.assign(value)
- x.assign_add(value_to_be_added)
- x.assign_sub(value_to_be_subtracted)
tf.reshape can be used to change the dimensions of the tensors. Example:
x = tf.constant([[3, 5, 7], [4, 6, 8]]),
y = tf.reshape(x, [3, 2]), gives the result
[[3, 5],
[7, 4],
[6, 8]
]
For more information on the structure of tensors, see https://www.tensorflow.org/guide/tensor
TensorFlow Data Pipeline
tf.data API
- Build complex input pipelines from simple, reusable pieces of code
- Build pipelines for multiple data types
- Handle large amounts of data; deal with complex operations
- Also integrates well with Keras, and is the recommended way of passing data through it.
In other words the TensorFlow Data Pipeline allows one to perform ETL operations in on large amounts of data, taken for example from numpy arrays, TFRecords, tabular data such as CSV files, Text, or Image data from different sources. The data from different sources can be unified and later processed in a pipeline using tf.data, next used to perform complex transformations, prior to training a model. It makes the data building pipeline process smooth the code more readable, reproducible, and reusable.
tf.data can read data from memory, and disk. It can also be used in a training loop, and for writing production input pipelines with feature engineering (batching, shuffling, etc.).
To set up a tf.data pipeline, one can use the abstraction tf.data.Datasets to set up a pipeline based on the TensorFlow Datasets object, then perform transformations on the dataset. Below is an example of setting up tf.data.Datasets for ETL ops:
First, fetch the input data. In this case, the data is fetched using Keras.
DATA_URL = 'https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz'
path = tf.keras.utils.get_file('mnist.npz', Data_URL),
Here, the .npz extension includes a set of stored Numpy arrays. Next the data set can be set up using the following command:
train_examples = data['x_train']
train_labels = data['y_train']
test_examples = data['x_test']
test_labels = data['y_test']Now you can create a tf.data.Dataset from numpy arrays using tf.data.Dataset.from_tensor_slices.
train_dataset = tf.data.Dataset.from_tensor_slices((train_examples, train_labels))
Similarly,
test_dataset = tf.data.Dataset.from_tensor_slices((test_examples, test_labels))
Now we have data ready for training and testing a model! A next step would be to build a build a tf.keras.Sequential, starting with the preprocessing_layer. See Keras Sequential API in the Keras docs for more information on this.
Dataset Optimization methods using tf.data.Dataset API
The tf.data.Dataset API provides optimization methods, such as the following
- Prefetching:
tf.data.Dataset.prefetchfetches future data required for training to reduce the the training and overall data load times. Note the difference between prefetching and multithreaded loading: Prefetching finds the parallelism within a single thread of execution, while multithreading exploits parallelism across multiple threads.
- Interleave: Data stored remotely causes overhead in when extracting the data, as it takes time to read from a remote server (e.g. the cloud), and also may require deserialization or decryption to properly load into a data set, which requires additional computation. To mitigate the overhead from data extraction, call
tf.data.Dataset.interleaveto improve performance by .- The sequential interleave Takes inputs from two or more datasets in different orders based on performance, and samples them in series.
- Parallel Interleave: process, by dividing data in separate logical threads (in parallel), then combine the data into a single dataset.
Resources:
Improving performance with tf.data API: https://www.tensorflow.org/guide/data_performance
Intro to TensorFlow pipelines: https://www.tensorflow.org/guide/data
To see how to load a CSV, check https://www.tensorflow.org/api_docs/python/tf/data/experimental
Feature Columns
Feature engineering is a very important task to achieve successful performance of ML models. It’s part of the preprocessing step, and typically entails various feature engineering tasks. These tasks typically involve scaling, bucketizing, generating interactions between variables, generating dummy variables, and applying domain-specific transformations. Feature engineering requires domain knowledge and some level of intuition about the relevant machine learning algorithm,
In support of feature engineering, Google provides tf.feature_columntf.feature_column
TensorFlow provides many types of feature columns. The most notable ones are Numeric Columns, Bucketized Columns, Categorical Columns, and Embedding Columns.
Numeric Column
A numeric column is the simplest type of column. It is used to represent real valued features. When using this column, your model will receive the column value from the dataframe unchanged.
Bucketized Column
Often, you don’t want to feed a number directly into the model, but instead split its value into different categories based on numerical ranges. Consider raw data that represents a person’s age. Instead of representing age as a numeric column, we could split the age into several buckets using a bucketized column.
Categorical Column
As we cannot pass strings directly onto a model, one-hot encodings are used to match strings. The categorical columns provide a way to represent strings as a one-hot vector. For example “Cat” or “Dog” can be assigned a numerical (1) value in an array, as a one-hot representations of the strings, for example:
cat = [0. 1.]
dog = [1. 0.]
one_hot_pets = [cat, dog]representing Cat, and Dog, respectively.
Embedding Column
Suppose instead of having just a few possible strings, we have thousands (or more) values per category. For a number of reasons, as the number of categories grow large, it becomes infeasible to train a neural network using one-hot encodings. To convert a sparse categorical column to a lower dimensional dense vector, one can define an an embedding column. We can use an embedding column to overcome this limitation. Instead of representing the data as a one-hot vector of many dimensions, an embedding column represents that data as a lower-dimensional, dense vector in which each cell can contain any number, not just 0 or 1.
Read More
https://www.tensorflow.org/tutorials/structured_data/feature_columns
https://aihub.cloud.google.com/u/0/p/products%2Fffd9bb2e-4917-4c80-acad-67b9427e5fde
Data Storage and Serialization
Prior to setting up a data pipeline, it’s recommended to prepare your data in a way that optimizes for usage with other TensorFlow modules, which includes your ETL ops, and model training. This is accomplished via binary data storage using TFRecord, and serialization through Protocol Buffers.
Data storage using TFRecord
The TFRecord format is a simple format for storing a sequence of binary records. Binary records are an efficient way to store data, as they have minimal processing overhead, i.e., they can be directly read into the pipeline, and as a consequence improve model training speed. Furthermore, as TFRecord is optimized for use with TensorFlow, which it makes it simple to work with other functions in the library, including data integration and preprocessing. It enables batch processing, and sequencing of data (such as time series or word encoding), for further convenience. For example, a TFRecord can be used as input to tf.data or tf.data.Dataset for data pipeline ops, via TFRecordDataset, containing multiple TFRecords.
Keep in mind that TFRecord file stores your data as a sequence of binary strings. Therefore, you need to specify the structure of your data before you write it to the file. Tensorflow provides two components for this purpose: tf.train.Example and tf.train.SequenceExample. You have to store each sample of your data in one of these structures, then serialize it and use a tf.python_io.TFRecordWriter to write it to disk.
Serialization using Protocol Buffers
To read data efficiently it can be helpful to first serialize your data and store it in a set of files (100-200MB each) that can each be read linearly. This is especially true if the data is being streamed over a network. This can also be useful for caching any data-preprocessing. To accomplish serialization, Google offers Protocol Buffers. Protocol messages are defined by .proto files, these are often the easiest way to understand a message type.
The tf.train.Example message (or protobuf) is a flexible message type that represents a {"string": value} mapping. It is designed for use with TensorFlow and is used throughout the higher-level APIs such as TFX. Fundamentally, a tf.Example is a {"string": tf.train.Feature} mapping.
TensorFlow Transform
TensorFlow Transform or tf.transform, is a library for preprocessing input data, to prepare for training. For example, transformation could include
- Normalizing an input value by mean and standard deviation.
- Convert strings into integers by generating a vocabulary over all input values.
- Convert floats to integers by assigning them to buckets based on the observed data distribution.
TensorFlow has built-in support for manipulations on a single example or a batch of examples. tf.Transform extends these capabilities to support full-passes over the example data.
Apache Beam Pipeline with tf.Transform
Apache Beam is a unified model for defining both batch and streaming data-parallel processing pipelines, as well as a set of language-specific SDKs for constructing pipelines and Runners for executing them on distributed processing backends, including Apache Flink, Apache Spark, Google Cloud Dataflow, and Hazelcast Jet.
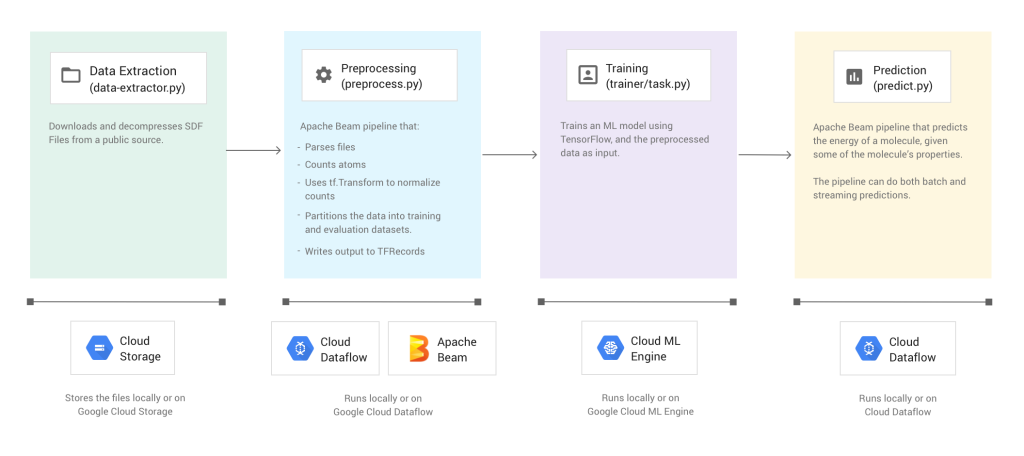
tf.Transform library for preprocessing, and writes the output to TFRecords.The output of tf.Transform is exported as a TensorFlow graph to use for training and serving, as seen in the image above. Using the same graph for both training and serving can prevent skew since the same transformations are applied in both stages.
References:
https://github.com/apache/beam
https://github.com/tensorflow/transform
https://www.tensorflow.org/tfx/transform/get_started
Further, a helpful introduction to tf.Transform can be found in the Dev Summit talk, below
TensorFlow Lite
Provides on-device inference of ML models on mobile devices. Essentially, the training step is performed on the cloud, but the inference step is performed on the mobile device.
Summary
In summary, consider the TensorFlow toolset when you start exploring larger models and/or datasets.
https://github.com/tensorflow/tensorflow
https://developers.google.com/machine-learning/crash-course/first-steps-with-tensorflow/toolkit
Other Resources
- Load text data – this link: https://www.tensorflow.org/tutorials/load_data/text
- TF.text – this link: https://www.tensorflow.org/tutorials/tensorflow_text/intro
- Load image data – https://www.tensorflow.org/tutorials/load_data/images
- Read data into a Pandas DataFrame – https://www.tensorflow.org/tutorials/load_data/pandas_dataframe
- How to represent Unicode strings in TensorFlow – https://www.tensorflow.org/tutorials/load_data/unicode
- TFRecord and tf.Example – https://www.tensorflow.org/tutorials/load_data/tfrecord